PassivePy Manual
Step 1.
Open your Python coding environment. We will use visual studio for this tutorial and suggest you install it too if you don’t already have a coding environment (link for installation). Make sure to install Python and Jupyter notebook by clicking on the Extensions icon (or ctrl + shift + x) and searching for python and Jupyter notebook.
Step 2.
In whatever coding environment you are, try creating a file. In Visual Studio, we right-click on the left side of the page and select “New File”. Type in the name and make sure to add “.ipynb” at the end.
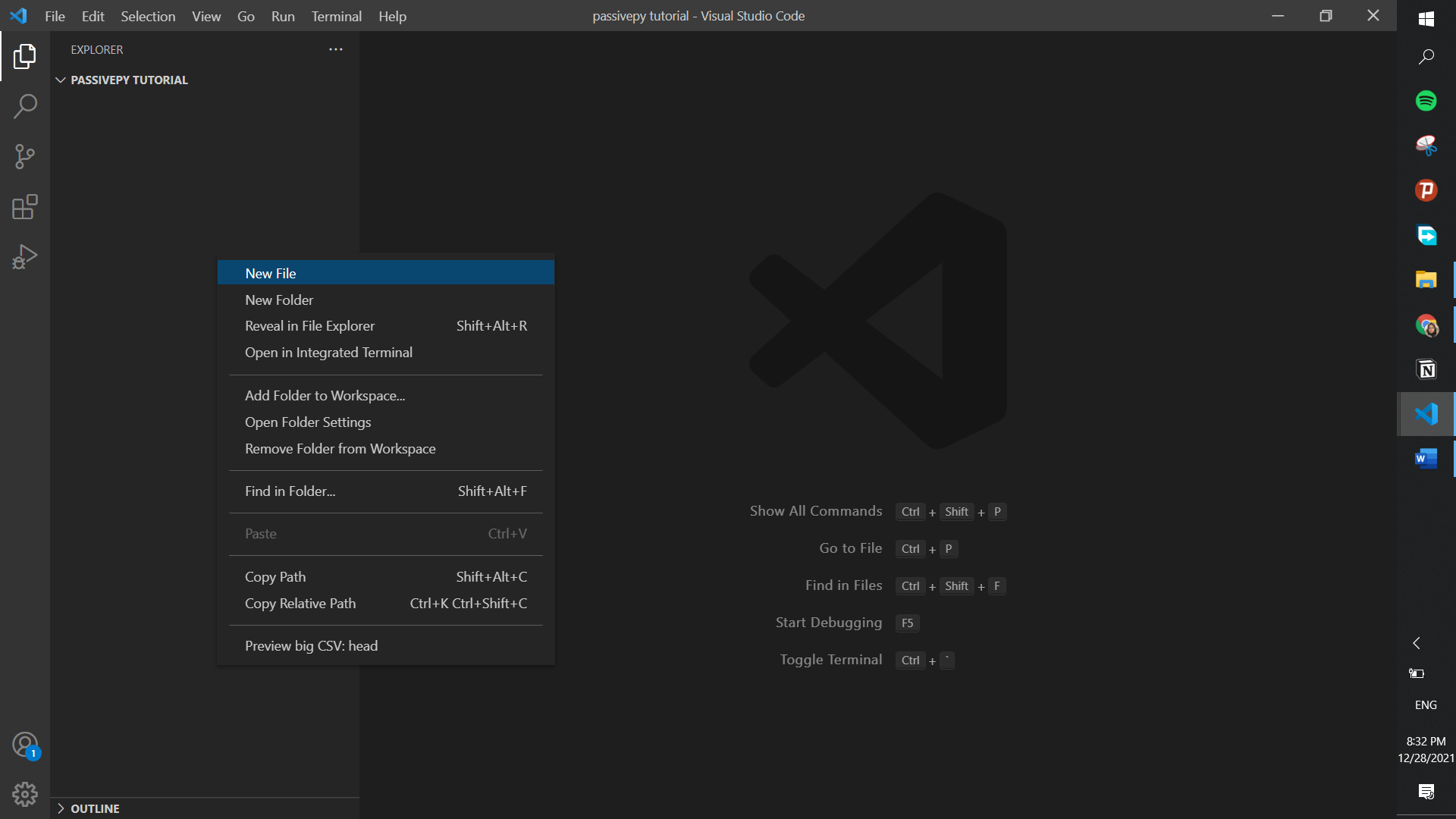
Step 3.
Name this file whatever you’d like. Just make sure that you add “ipynb” at the end. Here, we name our file “tutorial.ipynb”.
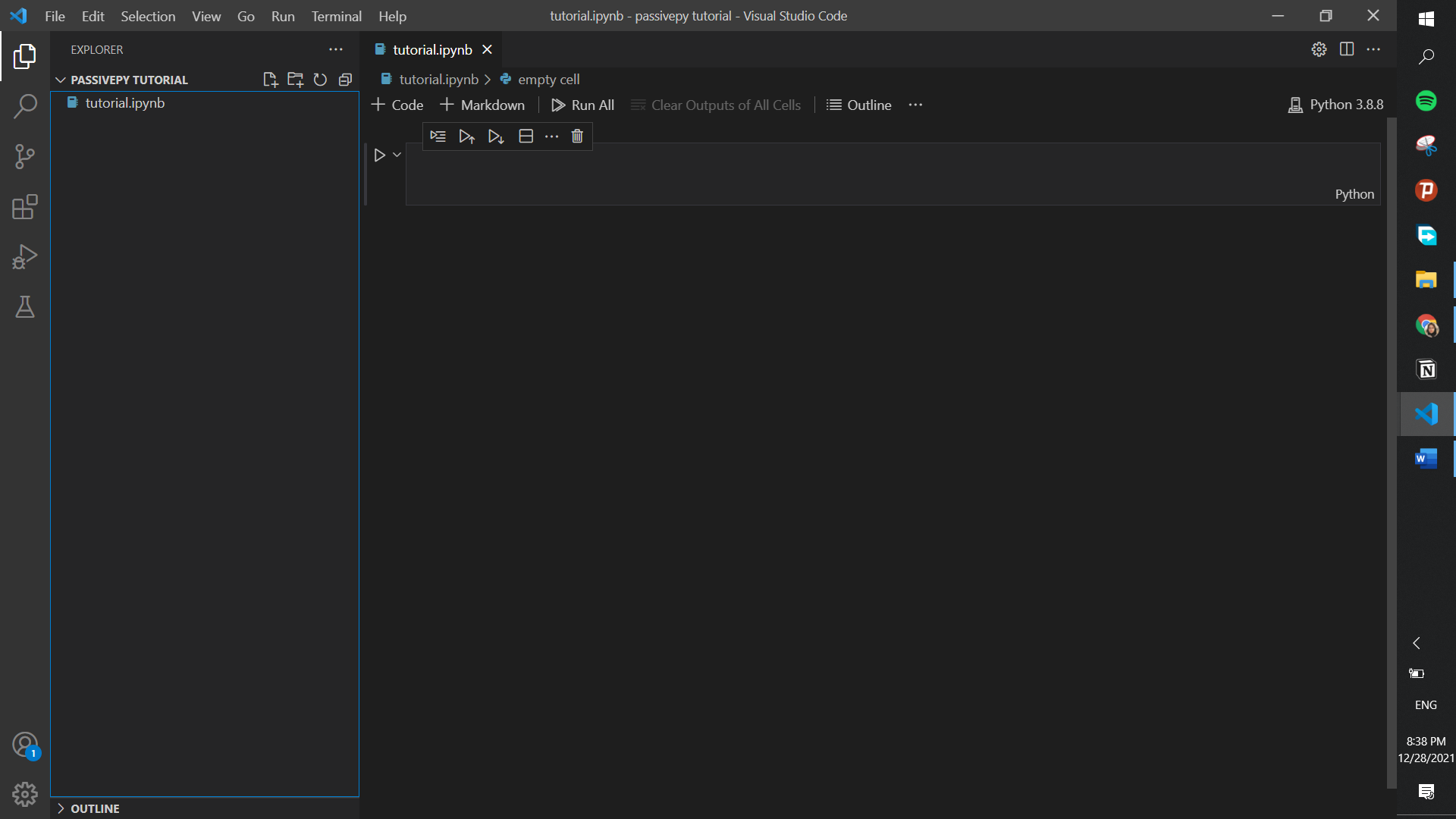
Step 4.
As you can see a cell has appeared on the page for us to start our code. First, we have to make sure that your system has all the requirements needed for the analysis. These requirements have been previously collected in a file and all you need to do is use !pip install to install them. Along with these requirements, we use another line of code to install the package itself. For all this, you can just copy and paste the following two lines.
!pip install -r https://raw.githubusercontent.com/mitramir55/PassivePy/main/PassivePyCode/PassivePySrc/requirements_lg.txt
!pip install PassivePy==0.2.13
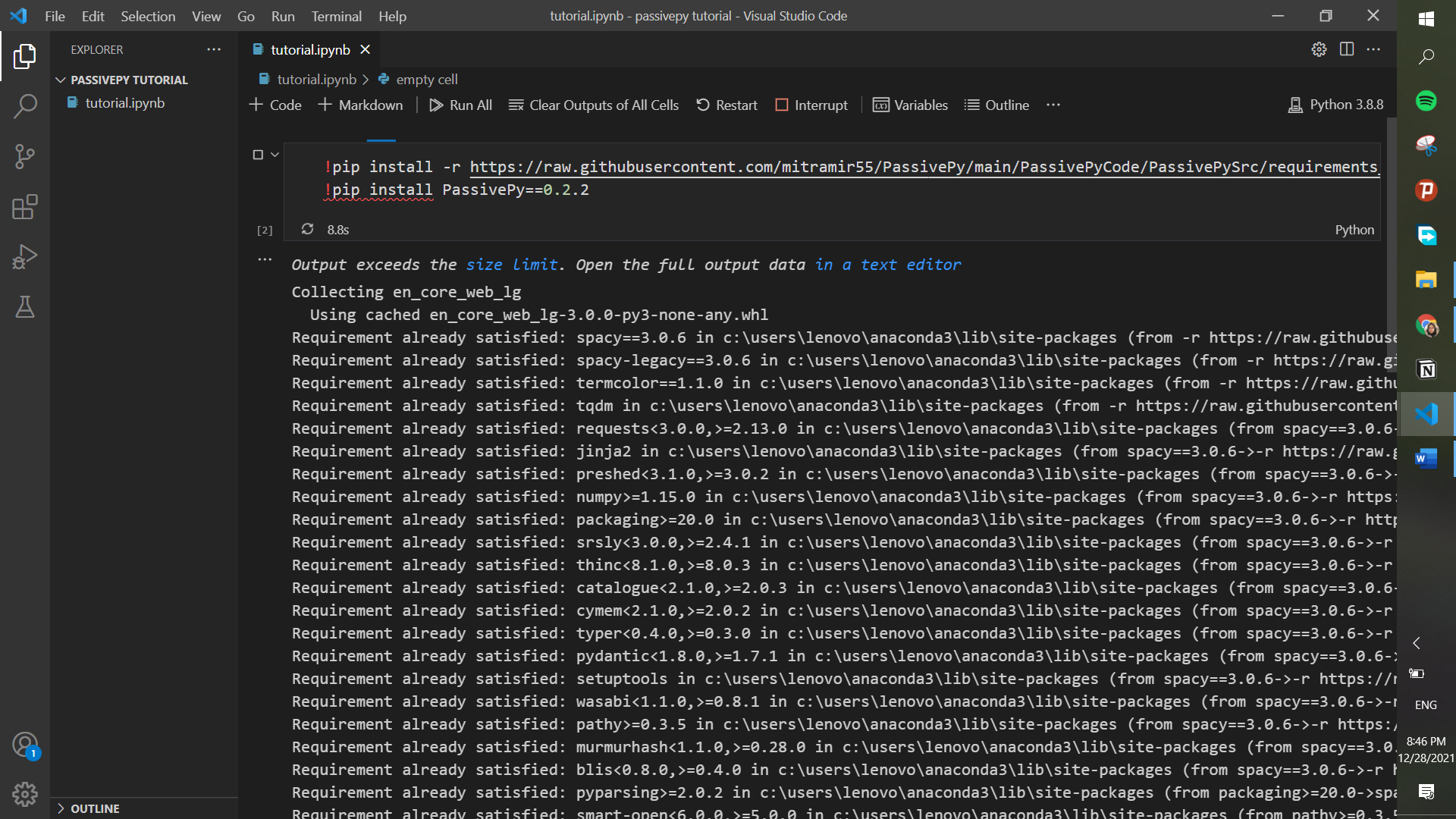
Step 5.
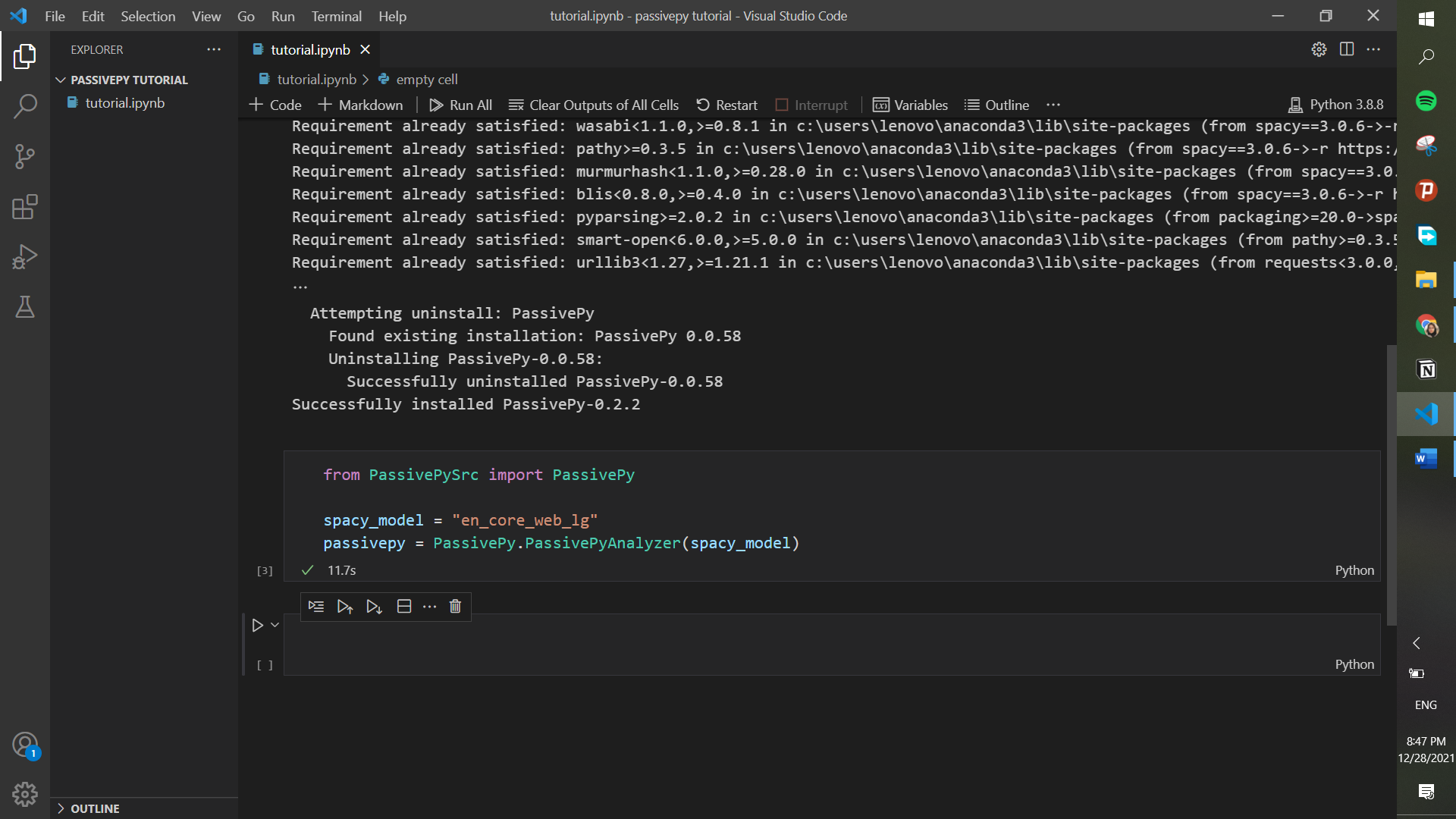
After the code stops running you will see a message at the end of all the outputted text that says, “PassivePy has been successfully installed”. Then, we can easily import and initial the package with the following lines:
from PassivePySrc import PassivePy
spacy_model = "en_core_web_lg"
passivepy = PassivePy.PassivePyAnalyzer(spacy_model)
Single-sentence Analysis
Sample Sentence Output
Now let’s experiment with PassivePy. Let’s say we have a sentence like “Natural resources are exhausted by humans.” And we would like to see if there’s any passive in this text. What we do is create a sample_text variable and input it to the function match_text of PassivePy. We want to see every type of passive, so we put True in front of truncated and full passive inside the brackets.
sample_text = "Natural resources are exhausted by humans."
result_1 = passivepy.match_text(sample_text, full_passive=True, truncated_passive=True)
result_1
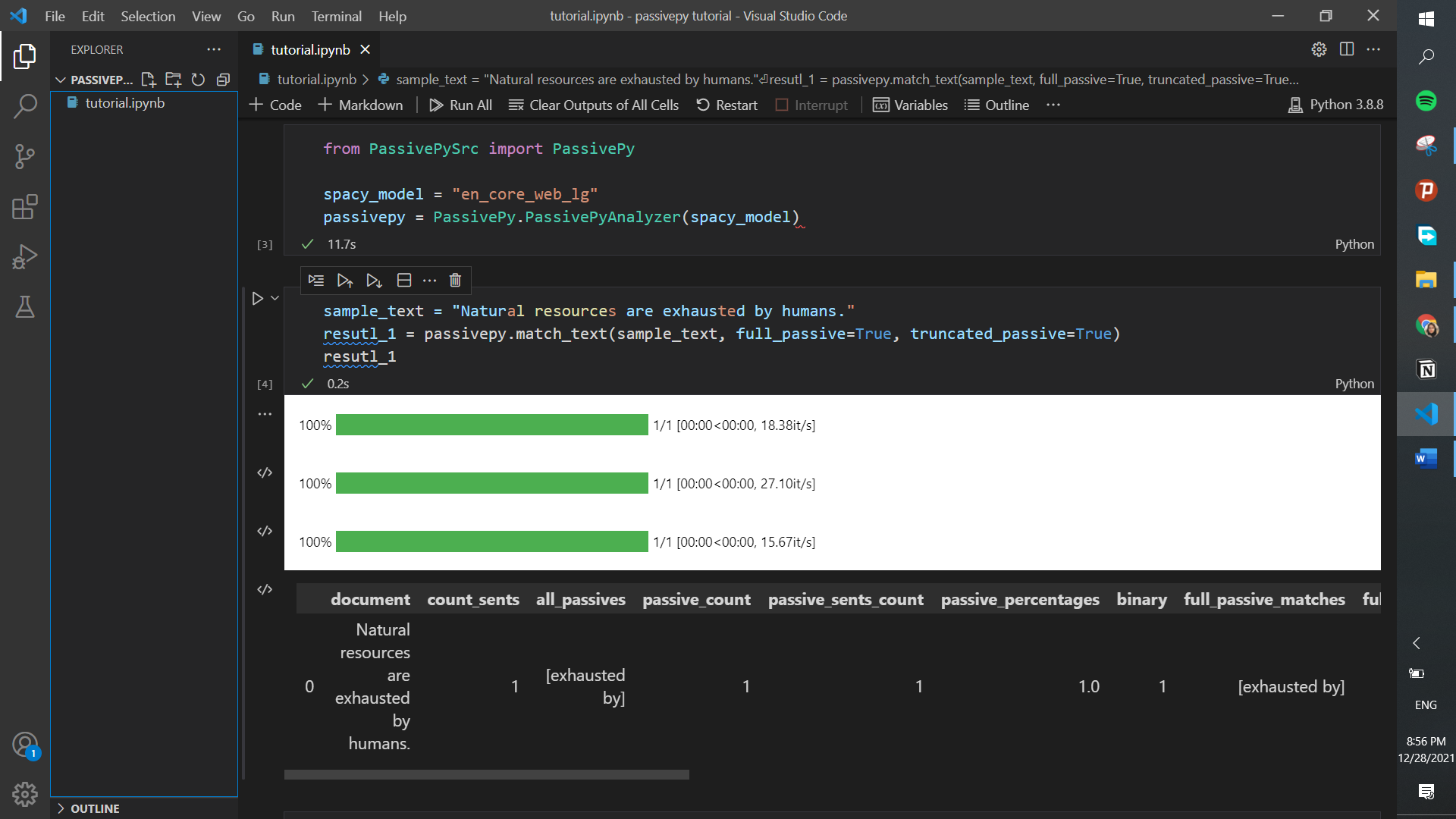
Parsing Sentences
If you had any question what tags each word had and which part of the text is passive, you can call the parse_sentence function of PassivePy:
passivepy.parse_sentence(sample_text)
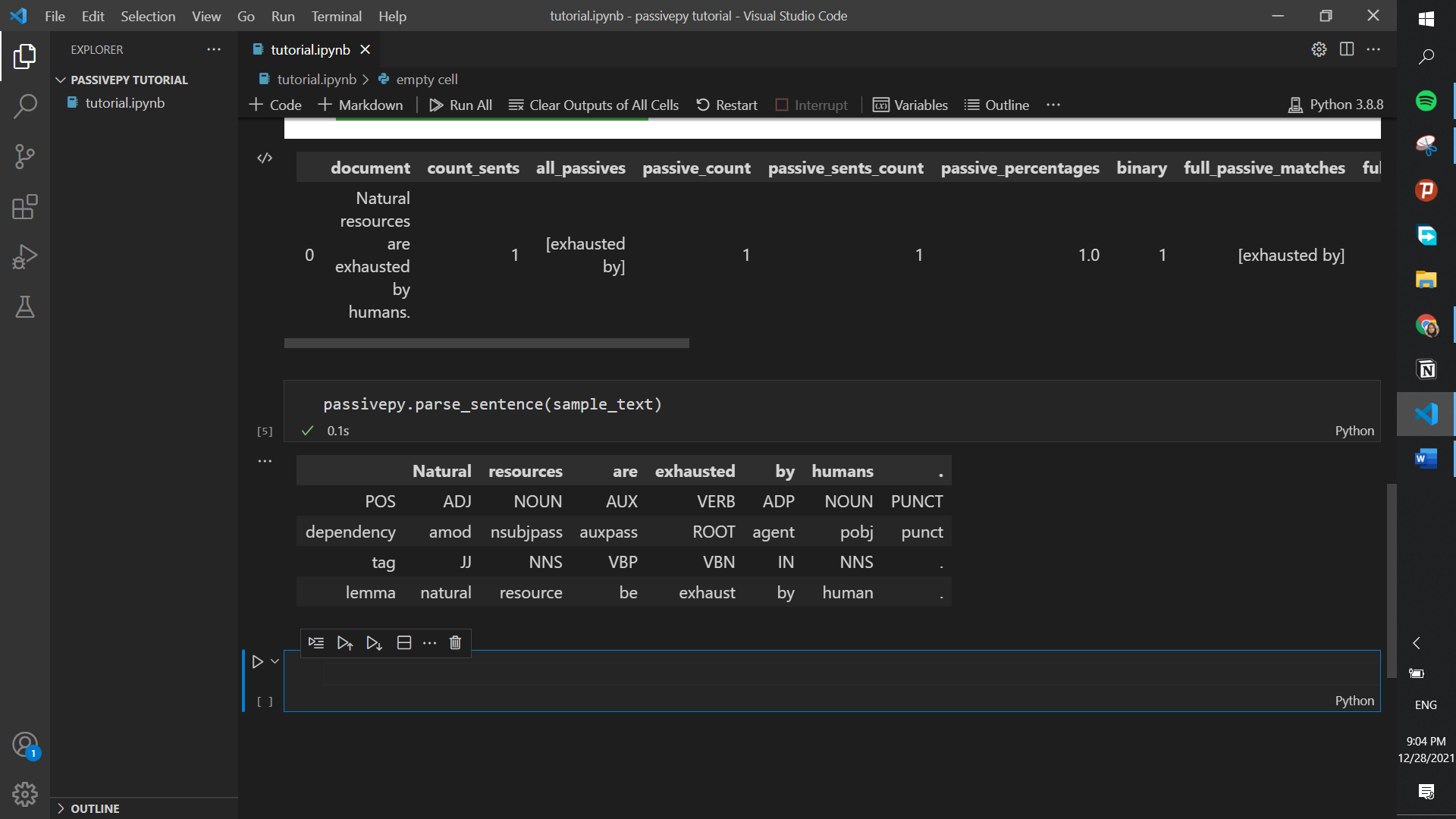
As you can see all words are listed on top and their DEP (dependency), POS (coarse-grained POS tags), TAG (fine-grained part of speech tags), LEMMA (canonical form) are listed below them. For detailed explanations on these tags, please visit: Stanford Dependencies Manual or spaCy’s Glossary.
Analyzing Datasets
For analyzing datasets in Python, we first need to import Pandas, with which we can read a dataset. Then, we specify the path to our dataset (where it is on our system) in the read_csv (for csv files) or read_xlsx (for excel files) to read the dataset. For our case, the dataset is on the Desktop and is named “sample_file.csv” if you want to find the path, just right-click on the file and copy the location property. Then extend the file path by adding the name of the file:
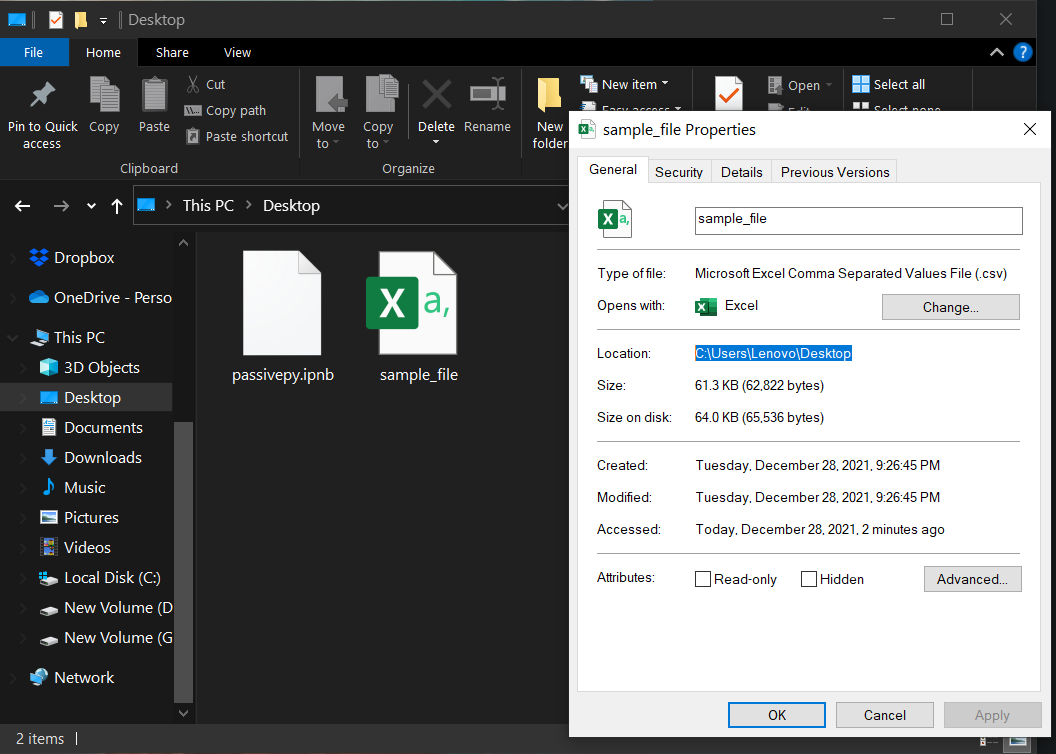
import pandas as pd
path_to_file = r'C:\Users\Lenovo\Desktop\sample_file.csv'
df = pd.read_csv(path_to_file)
Sentence-level Analysis
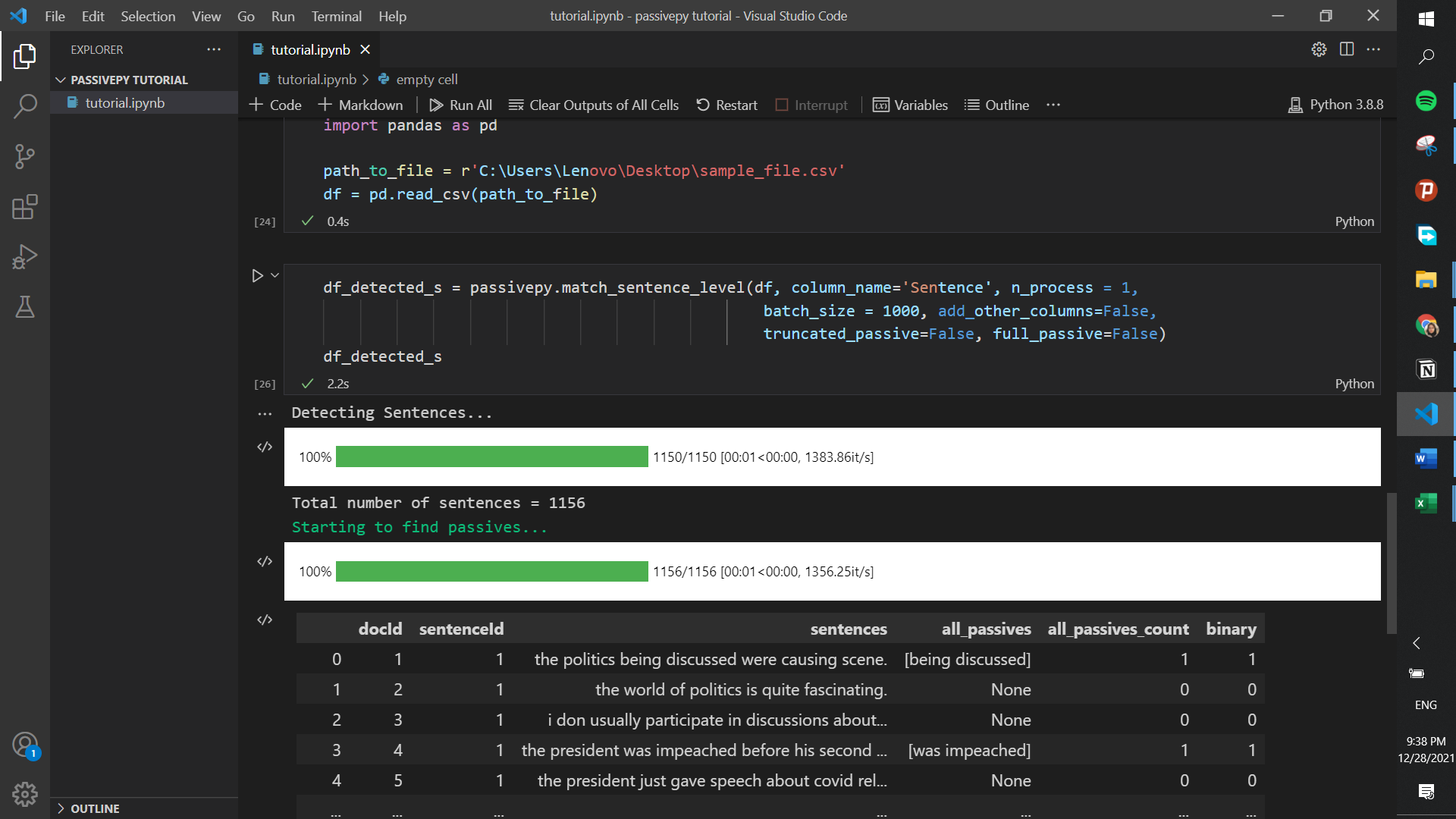
In this type of analysis, each row of a specific column (in this case our text is in the column named Sentences) will be broken down in sentences, and then their passives will be identified and put in separate columns.
df_detected_s = passivepy.match_sentence_level(df, column_name='Sentence', n_process = 1,
batch_size = 1000, add_other_columns=True,
truncated_passive=False, full_passive=False)
df_detected_s
Here are short descriptions of each column you see in the outputs:
| Column Name | Description |
|---|---|
| docId | Initial index of the record in the input file |
| sentenceId | The ith sentence in one specific record |
| sentence | The detected sentence |
| binary | Whether passive was detected in that sentence |
| passive_match(es) | The part of the record detected as passive voice |
| raw_passive_count | Number of passive forms detected in the sentence |
Corpus-level Analysis
In this type, each record will be viewed as a whole and all passives will be extracted, then various measures (such as percentage of passive, number of sentences, etc.) will be calculated for each record.
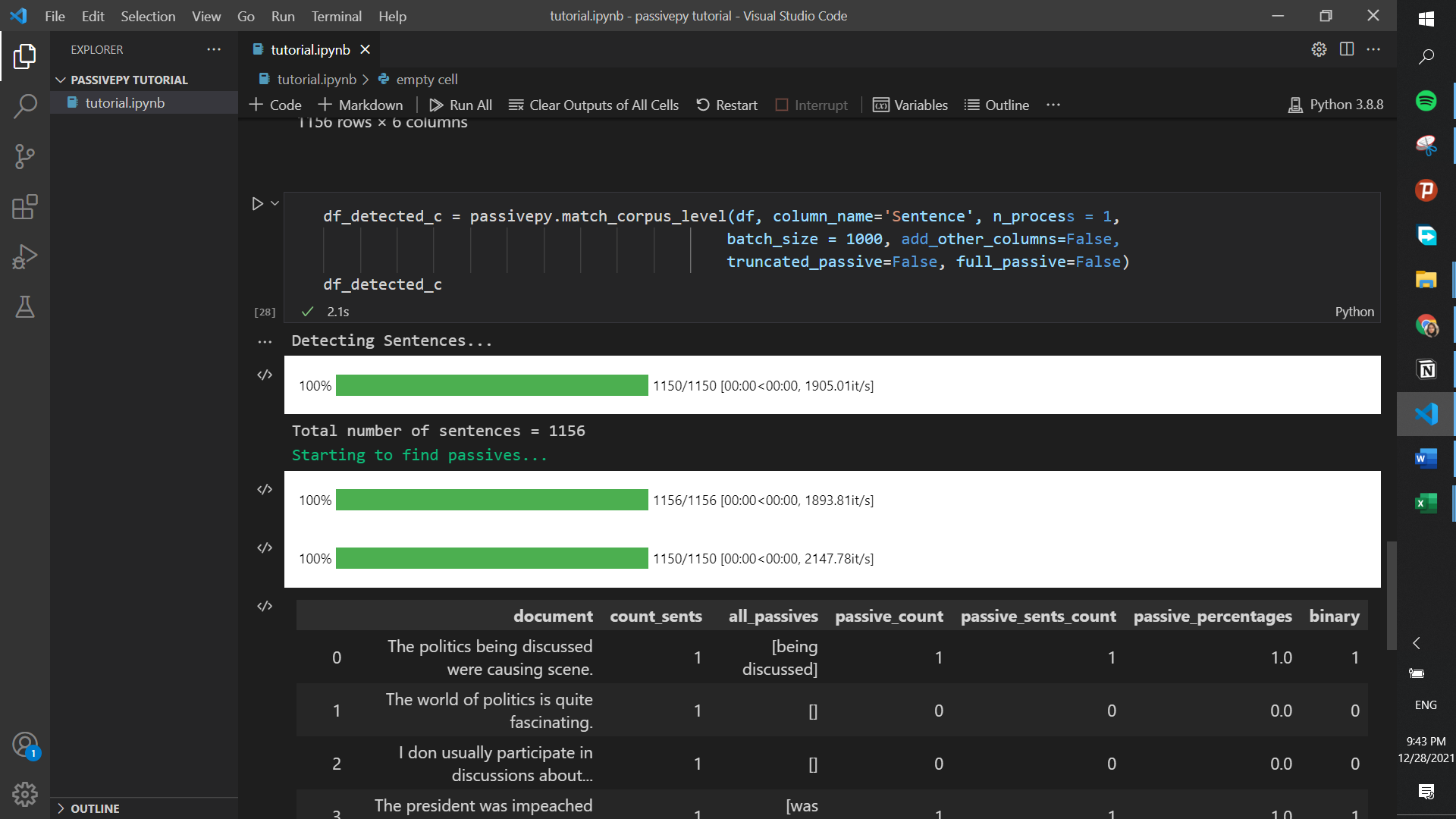
df_detected_c = passivepy.match_corpus_level(df, column_name='Sentence', n_process = 1,
batch_size = 1000, add_other_columns=True,
truncated_passive=False, full_passive=False)
df_detected_c
| Column Name | Description |
|---|---|
| document | Records in the input data frame |
| binary | Whether a passive was detected in that document |
| passive_match(es) | Parts of the document detected as passive |
| raw_passive_count | Number of passive voices detected in the sentence |
| raw_passive_sents_count | Number of sentences with passive voice |
| raw_sentence_count | Number of sentences detected in the document |
| passive_sents_percentage | Proportion of passive sentences to the total number of sentences |
OPTIONAL, BUT USEFUL:
- You can have pictures of words’ roles and their relationships with the following lines of code:
import spacy
from spacy import displacy
spacy_model = "en_core_web_lg"
nlp = spacy.load(spacy_model)
doc = nlp(text)
displacy.serve(doc, style = "dep", options={"compact":False})
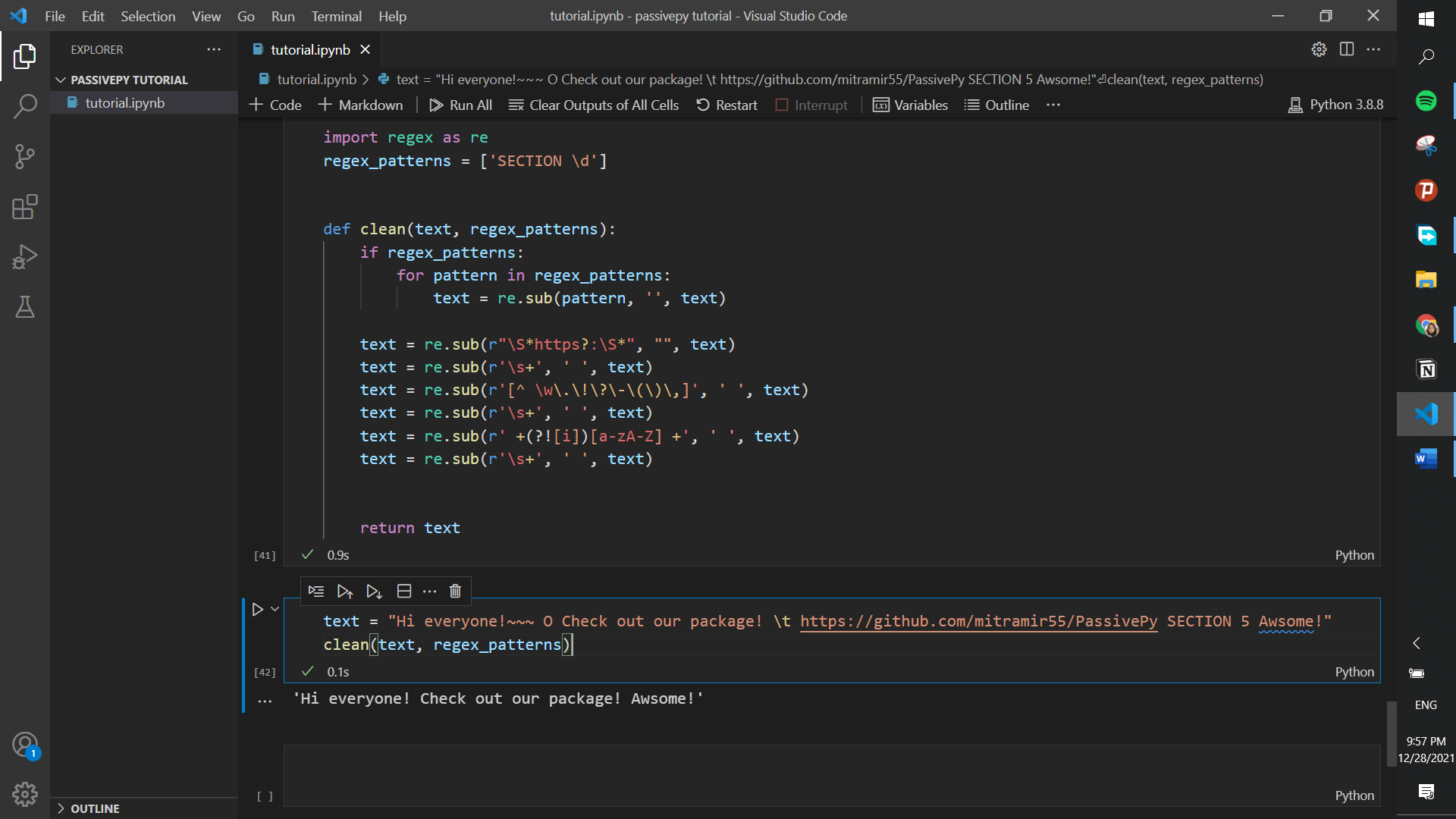
- You can clean your text with the following function. This removes all the unnecessary parts of a text (e.g., links, punctuations, and custom patterns) that might come in the way of your analysis and make your text unstructured.
import regex as re
regex_patterns = ['SECTION \d']
def clean(text, regex_patterns):
if regex_patterns:
for pattern in regex_patterns:
text = re.sub(pattern, '', text)
text = re.sub(r"\S*https?:\S*", "", text)
text = re.sub(r'\s+', ' ', text)
text = re.sub(r'[^ \w\.\!\?\-\(\)\,]', ' ', text)
text = re.sub(r'\s+', ' ', text)
text = re.sub(r' +(?![i])[a-zA-Z] +', ' ', text)
text = re.sub(r'\s+', ' ', text)
return text
text = "Hi everyone!~~~ O Check out our package! \t https://github.com/mitramir55/PassivePy SECTION 5 Awesome!"
clean(text, regex_patterns)
after cleaning the text, you can use it as an input to the package:
sample_text = clean("Natural resources are exhausted by humans.", regex_patterns)
result_1 = passivepy.match_text(sample_text, full_passive=True, truncated_passive=True)
result_1
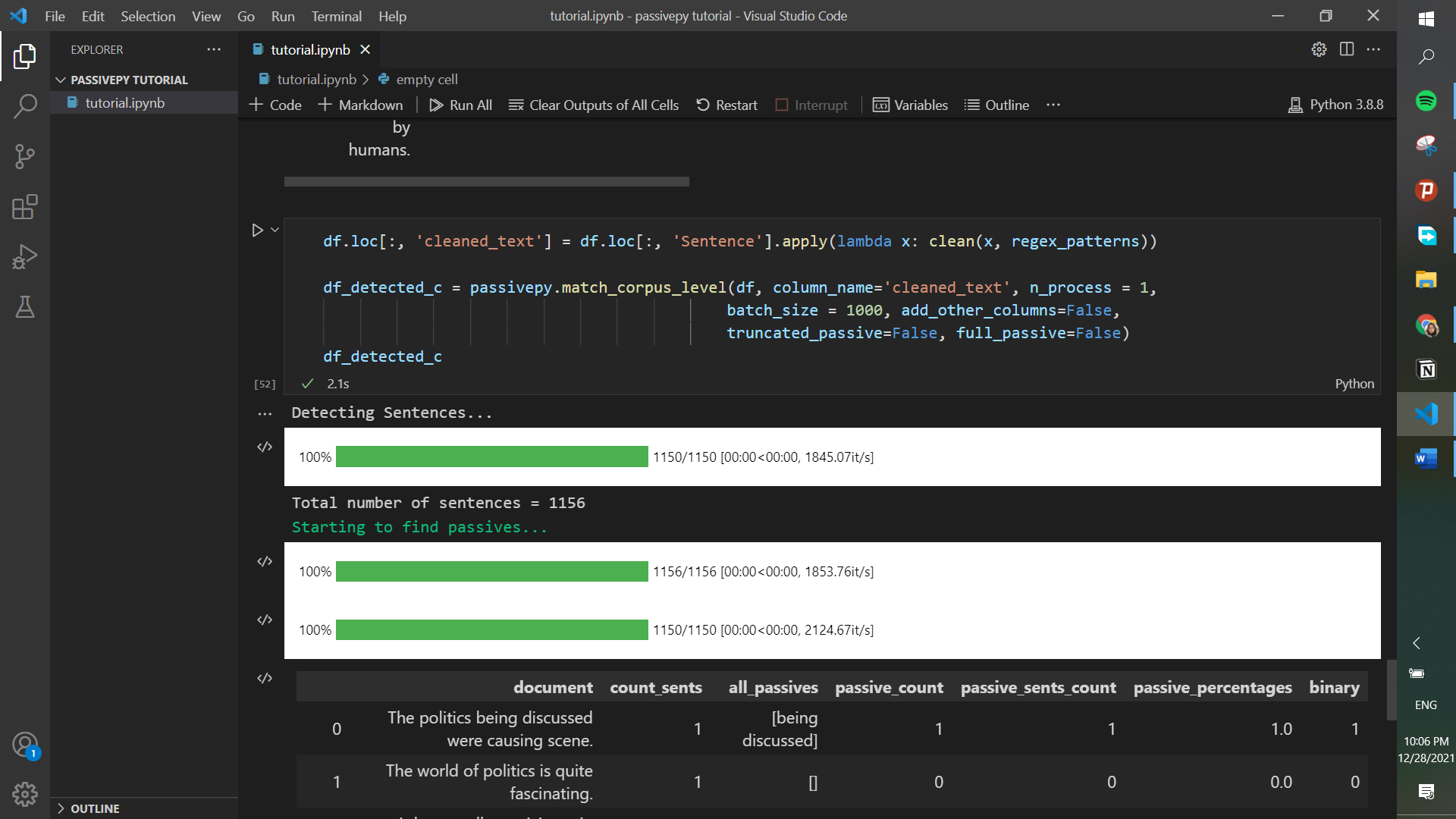
If you want to clean the text present in a column, you should first create a new column (for example called cleaned_text) and apply the cleaning function of all of the “Sentence” column records. Then, this “cleaned_text” column will be used for our analysis.
df.loc[:, 'cleaned_text'] = df.loc[:, 'Sentence'].apply(lambda x: clean(x, regex_patterns))
df_detected_c = passivepy.match_corpus_level(df, column_name='cleaned_text', n_process = 1,
batch_size = 1000, add_other_columns=False,
truncated_passive=False, full_passive=False)
df_detected_c
We hope you enjoyed using our package!